NoSQL 개요
NoSQL 개념
NoSQL은 키(Key)와 값(Value)의 형태로 자료를 저장하고, 빠르게 조회할 수 있는 자료 구조를 제공하는 저장소이다. 일반적인 DB인 RDBMS의 경우 조인(Join)을 수행할 수 있지만, NoSQL은 DB의 특성에 따라 Join 연산을 지원하거나 복잡한 Join을 지원하지 않으며 일반적으로 대용량 데이터와 대규모 확장성을 지원한다.
NoSQL은 원래 non-SQL(비 SQL) 혹은 non-relational(비 관계형)라는 의미로 쓰였으나, NoSQL DB에서 SQL을 지원하는 경우가 속속 등장하면서 현재는 Not only SQL이라고 말하기도 한다. [2]
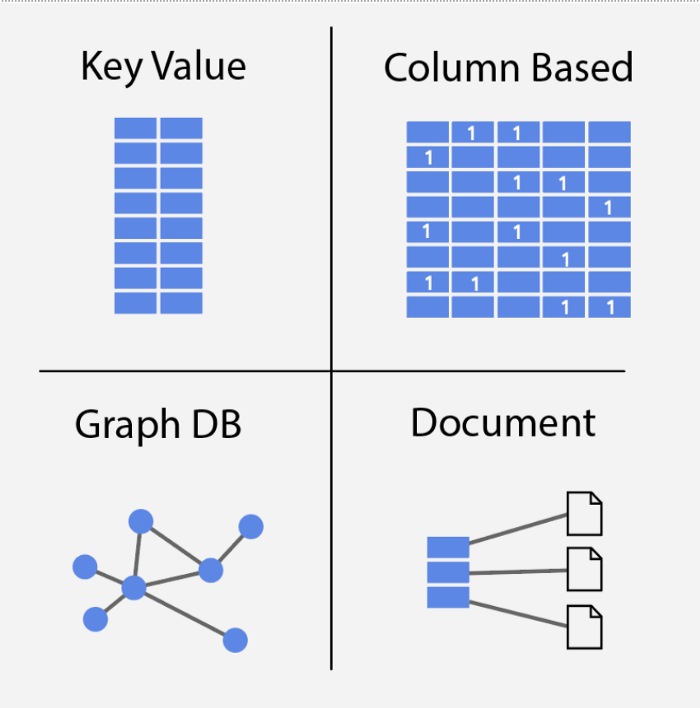
NoSQL의 경우 4가지 대표 유형의 DB가 존재하는데 키-값(KeyValue), 컬럼 기반(Column Based), 그래프(Graph DB), 문서(Document) 유형이 있다.
NoSQL의 유형들과 예시

구글 빅테이블(Google BigTable)
- 구글 자체적으로 대용량 데이터를 저장하기 위해 만든 것(2004년 시작)이 빅테이블이라는 분산 데이터 관리 저장소를 개발하였고, AppEngine이라는 플랫폼 서비스에서 사용하는 저장소이기도 하다. 구글 애널리틱스(Google Analytics), 웹 인덱싱(Web Indexing), 맵리듀스(Map Reduce)와 같은 여러 Google 어플리케이션에서 사용 된다. 현재는 클라우드 빅테이블이라는 명칭으로 서비스가 되고 있다.

데이터 모델
다차원 정렬 해시맵(multi-dimension sorted hash map)을 파티션하여 분산 저장하는 저장소이며, 테이블 내의 모든 데이터는 row-key와 column-family로 이루어져 있다. column-family는 다시 column-key와 value, timestamp 형태로 저장이 된다.

동일한 column-key에 타임스탬프가 다른 여러 버전이 존재할 수 있기에 하나의 데이터의 키 값 또는 정렬 기준은 "rowkey + columnkey + timestamp"가 된다. 파티션은 row-key를 이용하고, 분리된 파티션을 Tablet이라 하며, 한 Tablet은 100~200MB 정도이다.
페일오버(Fail Over)
특정 노드에서 장애가 발생하면 마스터 노드는 장애가 발생한 테블릿(Tablet)을 다른 노드로 재할당 시킨다. 할당 후 인덱스 파일, 데이터 파일 등을 이용하여 초기화 작업 수행 후 서비스를 수행한다.
구글 빅데이블은 공유 디스크(Shared Disk) 방식을 사용하고 있어, 모든 노드가 데이터, 인덱스 파일을 공유한다. SPOF(Single Point Of Failure)는 마스터로 분산 락(lock) 서비스를 제공하는 Chubby를 이용해 마스터를 모니터링 후 마스터 장애 발생시 다른 노드에 마스터 역할을 수행하도록 한다.
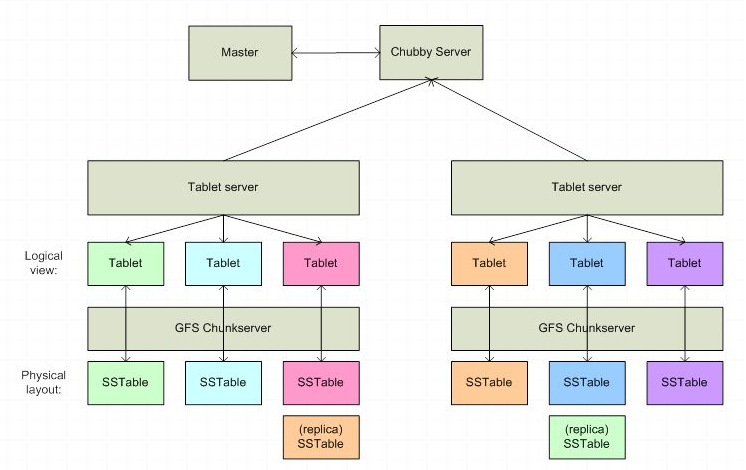
참고로 Chubby는 Fault-Tolerance 구조이기 때문에 절대로 장애가 발생하지 않는다.
AppEngine
AppEngine은 사용자에게 직접 빅테이블의 API를 공개하지 않고 추상 계층을 두고 있으며, API에 대한 추상화뿐만 아니라 데이터 모델에 대해서도 추상화되어 있다.
사용자가 테이블을 생성할 경우 빅테이블의 테이블로 생성하지 않고 특정 테이블의 한 영역만을 차지하며, 별도의 사용자 정의 인덱스(index)를 제공하지 않고, 사용자의 질의(Query, 쿼리)를 분석하여 자동으로 인덱스를 생성한다. 빅테이블 자체는 외부에 공개되지 않았으며, 비슷한 기능을 수행하는 솔루션으로 아파치 오픈소스인 HBase가 있다.

참고자료
[1] 데이터 분석 전문가 가이드 교재
[2] https://en.wikipedia.org/wiki/NoSQL
[3] https://en.wikipedia.org/wiki/Bigtable
연관포스팅
데이터베이스 클러스터(Database Cluster) - ADP #9
데이터베이스 클러스터(Database Cluster) - ADP #9
데이터베이스 클러스터의 개요 개념 - 데이터를 통합할 때 성능 향상과 가용성을 높이기 위해 DB 차원의 파티셔닝(Partitioning) 또는 클러스터링(Clustering)을 이용한다. - 파티셔닝은 용량이 큰 테이
needjarvis.tistory.com
'IT 자격증 > 데이터 분석 전문가(ADP)' 카테고리의 다른 글
| 데이터베이스 클러스터(Database Cluster) - ADP #9 (0) | 2022.07.19 |
|---|---|
| 분산 파일 시스템 (Distributed File System) - ADP #8 (0) | 2022.05.02 |
| 대용량 비정형 데이터 처리 - ADP #7 (0) | 2022.05.01 |
| 데이터 연계 및 통합 기법 - ADP #6 (0) | 2022.04.30 |
| EAI(Enterprise Application Integration) - ADP #5 (0) | 2022.04.01 |