
[Python] Beautiful Soup으로 크롤링하기 (기본편)
Beautiful Soup이란?
Beautiful Soup는 HTML 및 XML 문서를 파싱하기 위한 파이썬 라이브러리(Python Library)입니다. 웹 스크래핑(Web Scraping)에 사용되며, 복잡하고 비정형적인 웹 페이지로부터 필요한 데이터를 빠르고 쉽게 추출하는 것을 도와주고 있습니다.

Beautiful Soup 예제
from bs4 import BeautifulSoup
import requests
# 스크래핑할 URL
url = "https://needjarvis.tistory.com/802"
# 해당 url에 연결한 후 HTML 내용을 가져옵니다.
response = requests.get(url)
html_content = response.text
print(html_content)
위 예제를 실행할 때 만약 아래와 같이 에러가 발생한다면, 코드를 아래로 변경합니다.
에러 상황
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1131)
코드 교체
response = requests.get(url, verify=False)request.get 부분에서 verify=False 인자값을 추가합니다.
실행 결과
위와 같이 HTML의 내용을 정상적으로 가져온 것을 확인할 수 있습니다. 이제 이 HTML 태그를 파싱하여 스크래핑해보도록 하겠습니다.
제목 추출하기
제목을 추출해보도록 할텐데요. 그럴려면 사이트에서 제목이 어느 위치에 있는지를 알아야 합니다.
크롤링하는 URL의 제목의 경우 위 이미지 처럼 jb-content-title이라는 클래스에 담겨져 있기도 하며, 현재 포스팅의 경우 title 태그안에도 해당 제목으로 만들어져 있습니다.
우선 title 태그를 그냥 가지고 오는 예제를 보겠습니다.
from bs4 import BeautifulSoup
import requests
# 스크래핑할 URL
url = "https://needjarvis.tistory.com/802"
# 해당 url에 연결한 후 HTML 내용을 가져옵니다.
response = requests.get(url, verify=False)
html_content = response.text
# Beautiful Soup 객체로 파싱
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.find('title')
print(title)
위와 같이 title이라는 태그를 입력하면, title에 적힌 내용을 리턴하여 변수에 담게 됩니다. 이번에는 title 태그가 아니라 포스팅의 Html 태그를 캡쳐 했던 jb-content-title 클래스가 있는 태그값을 가져와보도록 하겠습니다.
from bs4 import BeautifulSoup
import requests
# 스크래핑할 URL
url = "https://needjarvis.tistory.com/802"
# 해당 url에 연결한 후 HTML 내용을 가져옵니다.
response = requests.get(url, verify=False)
html_content = response.text
# Beautiful Soup 객체로 파싱
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.find(class_='jb-content-title')
print(title)
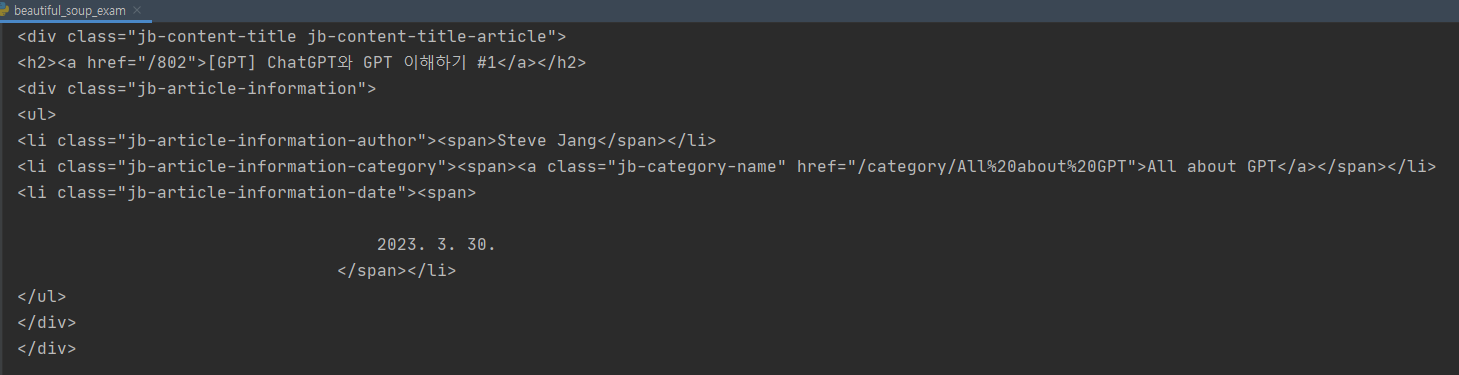
jb-content-title 클래스가 있는 태그값이 다른 값도 포함이 되어 있어서 보긴 그렇지만, 태그의 결과는 잘 가져오는 것을 확인할 수 있습니다. 이번에는 좀 더 심화로 jb-content-title > h2 > a 태그의 값을 가져와보도록 하겠습니다.
from bs4 import BeautifulSoup
import requests
# 스크래핑할 URL
url = "https://needjarvis.tistory.com/802"
# 해당 url에 연결한 후 HTML 내용을 가져옵니다.
response = requests.get(url, verify=False)
html_content = response.text
# Beautiful Soup 객체로 파싱
soup = BeautifulSoup(html_content, 'html.parser')
title = soup.select_one('.jb-content-title > h2 > a')
print(title)
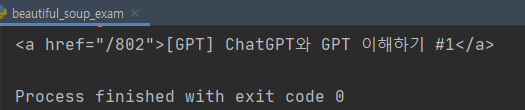
이전 예제와 차이점은 find를 사용하지 않고, select라는 메소드를 사용했다는 것입니다. select를 사용하면 css, jquery처 태그를 접근할 수 있어서 find보다 훨씬 사용하기 수월합니다.
이제 값을 가져왔으면, 태그를 제거해야 하는데요 태그를 제거하는 것과 beautiful soup의 다양한 메소드를 사용하는 방법은 다음 포스팅(심화편)에서 작성해보도록 하겠습니다.
참고자료
[1] https://beautiful-soup-4.readthedocs.io/en/latest/