[konlpy] 형태소 분석기별 명사(noun) 분석 속도 비교
- 인공지능 및 데이터과학/자연어처리
- 2021. 6. 12.
최근 konlpy 사이트에 적혀 있는 형태소 분석기의 분석 속도와 실제로 느꼈던 kolnpy의 개별 형태소 분석기의 성능이 맞지 않는 것 같아서 비교적 용량이 많은 문장을 기반으로 형태소 분석기의 성능을 체크해보려고 합니다.
실험에 사용된 형태소 분석기는 총 3종인 코모란(Komoran), 꼬꼬마(Kkma), Okt(Open korean text)이며 꼬꼬마는 분석속도가 나쁜 것이 체감이 날 정도로 좋지 않지만 코모란과 okt의 분석 속도도 예상 밖인것 같아서 제대로 시간을 체크하고자 하였습니다.

공통코드
import urllib.request
import time
from konlpy.tag import Okt
from konlpy.tag import Komoran
from konlpy.tag import Kkma
import matplotlib.pyplot as plt
urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
def set_review_data(file_nm):
with open(file_nm, "r", encoding="utf8") as f:
data = [line.split('\t') for line in f.read().splitlines()]
return data[1:20001]
start_time = time.time()
print('[BEGIN] 리뷰 데이터를 읽는다.')
review_data = set_review_data('ratings.txt')
print('review_data size->', len(review_data))
print('[END] 리뷰 데이터를 읽는다. (', time.time() - start_time, ')sec')아래 데이터는 ratings.txt 파일의 일부이며 약 20만개로 이루어진 리뷰 데이터입니다. 비교적 대용량 데이터인데 이렇게 많은 용량을 형태소 분석기별로 테스트를 진행하니 시간이 오래 걸리고 out of memory도 뜨곤 해서, 2만개만 사용하는 것으로 변경하였습니다.
id document label
8112052 어릴때보고 지금다시봐도 재밌어요ㅋㅋ1
8132799 디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업이 부러웠는데. 사실 우리나라에서도 그 어려운시절에 끝까지 열정을 지킨 노라노 같은 전통이있어 저와 같은 사람들이 꿈을 꾸고 이뤄나갈 수 있다는 것에 감사합니다.1
4655635 폴리스스토리 시리즈는 1부터 뉴까지 버릴께 하나도 없음.. 최고.1
9251303 와.. 연기가 진짜 개쩔구나.. 지루할거라고 생각했는데 몰입해서 봤다.. 그래 이런게 진짜 영화지
1
10067386 안개 자욱한 밤하늘에 떠 있는 초승달 같은 영화.1
2190435 사랑을 해본사람이라면 처음부터 끝까지 웃을수 있는영화 1
kolnpy_perform = {}
print(review_data[1][1])
# 디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업이 부러웠는데. 사실 우리나라에서도 그 어려운시절에 끝까지 열정을 지킨 노라노 같은 전통이있어 저와 같은 사람들이 꿈을 꾸고 이뤄나갈 수 있다는 것에 감사합니다.형태소 분석기의 퀄리티를 비교해보고자 비교적 문장이 긴 2번째 리뷰 데이터를 화면에 출력해보았습니다.
꼬꼬마(Kkma)
start_time = time.time()
kkma = Kkma()
nouns = [kkma.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['kkma'] = time.time() - start_time
print('꼬꼬마 명사 추출 (', kolnpy_perform['kkma'], ')sec')우선 서울대학교에서 만든것으로 알려진 Kkma 분석기 입니다. 다른 형태소 분석기에 비해서 분석 퀄리티가 뛰어난 것으로 유명합니다. 다만 치명적인 단점으로 속도가 있어서 대용량을 다룬다던지 실시간으로 처리하는 부분에서 사용되기가 쉽지 않습니다.
꼬꼬마 프로젝트는 서울대학교 IDS (Intelligent Data Systems) 연구실에서 자연어 처리를 하기 위한 다양한 모듈 및 자료를 구축하기 위한 과제로 크게 '형태소 분석기 및 자연어 처리 모듈 개발' 부분과 '세종 말뭉치 활용 시스템'으로 구분된다.
코모란(Komoran)
start_time = time.time()
komoran = Komoran()
nouns = [komoran.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['komoran'] = time.time() - start_time
print('코모란 명사 추출 (', kolnpy_perform['komoran'], ')sec')두번째 타자로는 Java 형태소 분석기를 사용하는 사람들이라면 안써본 사람이 없을 것 같은 코모란 입니다. 사이트에 충분히 쓰일만한 속도와 형태소 분석 퀄리티를 비교적 잘 잡은 균형있는 형태소 분석기입니다.
Okt (Open Korean Text) (주)트위터분석기
start_time = time.time()
okt = Okt()
nouns = [okt.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['okt'] = time.time() - start_time
print('OKT 명사 추출 (', kolnpy_perform['okt'], ')sec')OKT는 트위터분석기라는 이름으로 진행되었던 프로젝트가 fork되어 진행되는 것으로 기본적으로 베이스는 트위터 분석기입니다. okt는 형태소 분석기를 표방하지 않고 형태소 처리기라는 용어를 사용합니다.
그래프 출력
# 그래프 출력
plt.bar(*zip(*kolnpy_perform.items()))
plt.show()최종적으로 matplotlib의 bar형태로 속도를 가시화(Visualization) 합니다.
결과
[BEGIN] 리뷰 데이터를 읽는다.
review_data size-> 20000
[END] 리뷰 데이터를 읽는다. ( 0.35405564308166504 )sec
디자인을 배우는 학생으로, 외국디자이너와 그들이 일군 전통을 통해 발전해가는 문화산업이 부러웠는데. 사실 우리나라에서도 그 어려운시절에 끝까지 열정을 지킨 노라노 같은 전통이있어 저와 같은 사람들이 꿈을 꾸고 이뤄나갈 수 있다는 것에 감사합니다.
['디자인', '학생', '외국', '외국디자이너', '디자이너', '그', '전통', '발전', '문화', '문화산업', '산업', '사실', '우리', '우리나라', '나라', '시절', '끝', '열정', '노', '저', '사람', '꿈', '수', '감사']
꼬꼬마 명사 추출 ( 396.63582849502563 )sec
['디자인', '학생', '외국', '디자이너', '전통', '발전', '문화', '산업', '사실', '우리나라', '시절', '끝', '열정', '노라', '노', '전통', '사람', '꿈', '수', '것', '감사']
코모란 명사 추출 ( 24.129064559936523 )sec
['디자인', '학생', '외국', '디자이너', '그', '일군', '전통', '통해', '발전', '문화', '산업', '사실', '우리나라', '그', '시절', '끝', '열정', '노라노', '전통', '저', '사람', '꿈', '수', '것']
OKT 명사 추출 ( 59.397358655929565 )sec
대체적으로 형태소 분석기의 분석 퀄리티는 꼬꼬마 > OKT >= 코모란으로 보이며, 코모란의 경우 대명사(ex: 그들)과 같은 경우 뽑지 않지만 OKT는 감사합니다에서 감사같은 명사를 뽑지 않는 것에서 의외였습니다. kkma는 자체적으로 복합명사를 추가적으로 뽑아내서 퀄리티가 확실히 더 좋습니다.
외국디자이너의 경우 다른 형태소 분석기는 이 둘을 분리하여 외국+디자이너로 나누지만 꼬꼬마는 외국, 디자이너, 외국디자이너를 모두 뽑아내기에 속도가 중요하지 않거나 한번 추출만 해야 하는 경우 kkma를 쓰는 것이 좋아보입니다.
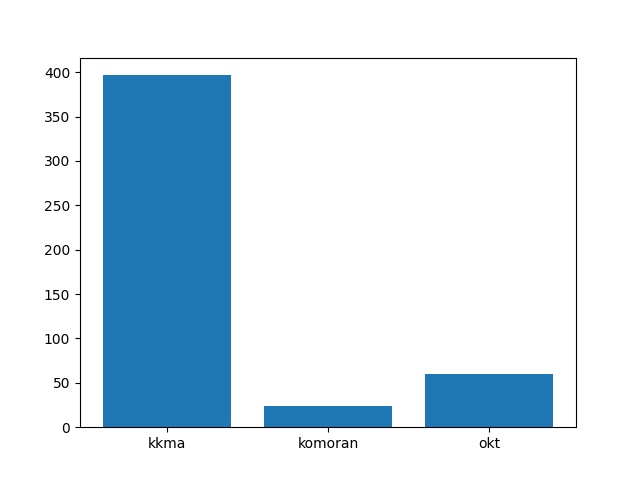
결론적으로 꼬꼬마는 396초, 코모란의 경우 24초, OKT는 59초 정도 걸렸고, 약 2만건의 데이터니 초당 꼬꼬마는 50개의 리뷰, 코모란은 833개, OKT는 338개를 처리하니 하루 사용량이 적고 실시간 처리가 필요 없을 경우 꼬꼬마를 그외에는 코모란이나 OKT를 사용하는 것이 좋아보입니다.
이건 명사속도 분석 결과이고, 다음에는 우리가 흔히 형태소 분석이라 표현하는 Pos-Tagging (품사태깅) 속도를 비교해볼까 합니다.
전체 소스
import urllib.request
import time
from konlpy.tag import Okt
from konlpy.tag import Komoran
from konlpy.tag import Kkma
import matplotlib.pyplot as plt
#urllib.request.urlretrieve("https://raw.githubusercontent.com/e9t/nsmc/master/ratings.txt", filename="ratings.txt")
def set_review_data(file_nm):
with open(file_nm, "r", encoding="utf8") as f:
data = [line.split('\t') for line in f.read().splitlines()]
return data[1:50001]
start_time = time.time()
print('[BEGIN] 리뷰 데이터를 읽는다.')
review_data = set_review_data('ratings.txt')
print('review_data size->', len(review_data))
print('[END] 리뷰 데이터를 읽는다. (', time.time() - start_time, ')sec')
kolnpy_perform = {}
print(review_data[1][1])
start_time = time.time()
kkma = Kkma()
nouns = [kkma.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['kkma'] = time.time() - start_time
print('꼬꼬마 명사 추출 (', kolnpy_perform['kkma'], ')sec')
start_time = time.time()
komoran = Komoran()
nouns = [komoran.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['komoran'] = time.time() - start_time
print('코모란 명사 추출 (', kolnpy_perform['komoran'], ')sec')
start_time = time.time()
okt = Okt()
nouns = [okt.nouns(datas[1]) for datas in review_data]
print(nouns[1])
kolnpy_perform['okt'] = time.time() - start_time
print('OKT 명사 추출 (', kolnpy_perform['okt'], ')sec')
# 그래프 출력
plt.bar(*zip(*kolnpy_perform.items()))
plt.show()
연관포스팅
[kolnpy] 형태소 분석기별 품사 태깅(Pos-Tagging) 비교
'인공지능 및 데이터과학 > 자연어처리' 카테고리의 다른 글
| 한자 추출 및 인식하기 (0) | 2021.07.02 |
|---|---|
| [konlpy] 형태소 분석기별 품사 태깅(Pos-Tagging) 비교 (1) | 2021.06.12 |
| 패스트텍스트(FastText) #1, 개념 이해하기 (0) | 2021.06.06 |
| [Java] TF-IDF 개념과 자바로 구현 (0) | 2021.05.27 |
| Word2Vec #3, 모델 활용(사용)하기 (0) | 2021.05.20 |