데이터 분석을 해야 하거나 할 줄 아는 사람이라면 처음에 데이터의 형태를 파악해야 할텐데 히스토그램(Histogram)은 데이터의 분포도를 볼 때 매우 유용한 통계 시각화 기법이다.
원래 통계 기법은 R이 상징적인 언어였으나 최근에는 데이터 분석을 하는 사람들이 굳이 R로 하지 않고 파이썬에서 하는 경우가 많아졌다.
히스토그램용 데이터 가져오기 (housing dataset)
import os
import tarfile
import urllib.request as urllib
import pandas as pd
data_url = "https://raw.githubusercontent.com/ageron/handson-ml2/master/datasets/housing/housing.tgz"
data_path = os.path.join("datasets", "housing")
# 외부 url을 호출하여, housing data를 저장한다
def fetch_housing_data():
os.makedirs(data_path, exist_ok=True)
tgz_path = os.path.join(data_path, "housing.tgz")
urllib.urlretrieve(data_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=data_path)
housing_tgz.close()
# housing 데이터를 판다스 형태로 읽는다
def load_housing_data():
csv_path = os.path.join(data_path, "housing.csv")
return pd.read_csv(csv_path)
fetch_housing_data()
housing = load_housing_data()
위 데이터는 데이터 분석에서 많이 쓰이는 캘리포니아 주택 가격 예측 데이터셋이다.
print(housing.info())
print(housing.head())위와 같이 info와 head로 데이터의 정보를 보면
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 longitude 20640 non-null float64
1 latitude 20640 non-null float64
2 housing_median_age 20640 non-null float64
3 total_rooms 20640 non-null float64
4 total_bedrooms 20433 non-null float64
5 population 20640 non-null float64
6 households 20640 non-null float64
7 median_income 20640 non-null float64
8 median_house_value 20640 non-null float64
9 ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
None
longitude latitude ... median_house_value ocean_proximity
0 -122.23 37.88 ... 452600.0 NEAR BAY
1 -122.22 37.86 ... 358500.0 NEAR BAY
2 -122.24 37.85 ... 352100.0 NEAR BAY
3 -122.25 37.85 ... 341300.0 NEAR BAY
4 -122.25 37.85 ... 342200.0 NEAR BAY10개의 컬럼이 있고, 데이터가 어떻게 들어가 있는지 알 수 있다.
housing column info
| longitude | 위도 |
| latitude | 경도 |
| housing_median_age | 주택 나이 중앙값(median) |
| total_rooms | 전체 방의 수 |
| total_bedrooms | 전체 침실 수 |
| population | 인구 |
| households | 가구 |
| median_income | 소득 중앙값 |
| median_house_value | 주택 가격 중앙값 |
| ocean_proximity | 바다 근접성 |
이제 이 10개의 컬럼을 각각 히스토그램으로 뿌려보는 작업을 진행해 보도록 한다.
Matplotlib 히스토그램
대표적으로 가장 많이 활용되는 Matplotlib 시각화 라이브러리를 활용하여, 히스토그램을 호출하는 방법을 사용하였다.
import matplotlib.pyplot as plt
# histogram source
housing.hist(bins=50, figsize=(20,15))
plt.show()
bins
그래프 개수
ex) bins=50
figsize
그래프의 크기
ex) figsize=(가로크기, 세로크기)
Housing dataset 출력 결과
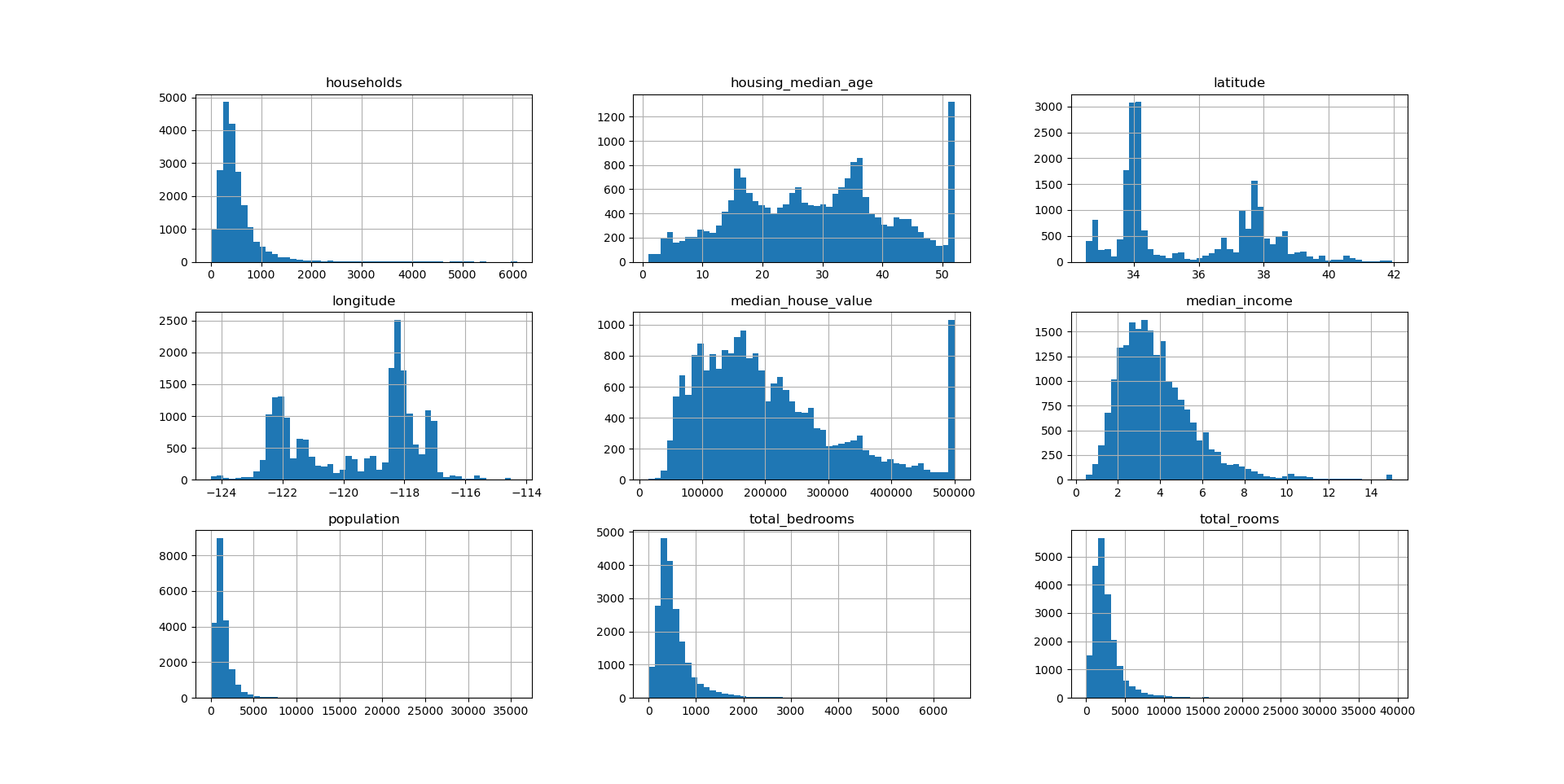
housing dataset의 히스토그램을 뽑아보았는데 컬럼이 총 10개인데 9개만 출력되는 이유는 ocean_proximity가 문자열로 되어 있기 때문이다.
longitude,latitude,housing_median_age,total_rooms,total_bedrooms,population,households,median_income,median_house_value,ocean_proximity
-122.23,37.88,41.0,880.0,129.0,322.0,126.0,8.3252,452600.0,NEAR BAY
-122.22,37.86,21.0,7099.0,1106.0,2401.0,1138.0,8.3014,358500.0,NEAR BAY
-122.24,37.85,52.0,1467.0,190.0,496.0,177.0,7.2574,352100.0,NEAR BAY
-122.25,37.85,52.0,1274.0,235.0,558.0,219.0,5.6431,341300.0,NEAR BAY
히스토그램은 연속될 수 있는 숫자만 출력할 수 있기 때문에 문자열인 바다 근접도는 출력이 되지 않고 출력이 가능한 것만 출력을 수행하였다.
'인공지능 및 데이터과학 > 데이터분석 & 통계' 카테고리의 다른 글
| [데이터분석] 정보 이득(Information Gain) 이해하기(feat. 엔트로피) (0) | 2022.02.03 |
|---|---|
| [데이터분석] 엔트로피(Entropy) 이해하기 (0) | 2022.01.31 |
| [Python] 판다스(Pandas)로 데이터 확인 및 기초통계 하기 (0) | 2021.05.28 |
| 확률의 함정을 간파, 베이즈 정리(Bayes' Theorem) (2) | 2020.12.13 |
| 코사인 유사도(Cosine similarity) 이해 및 Java로 구현하기 (0) | 2020.04.13 |