대용량 비정형 데이터 처리 - ADP #7
- IT 자격증 / 데이터 분석 전문가(ADP)
- 2022. 5. 1.
1. 대용량 로그 데이터 수집
- 로그(Log)는 기업에서 발생하는 대표적인 비정형 데이터
- 과거에는 시스템의 문제 상황, 서비스 접근, 사용 로그를 기록하는 용도
- 최근에는 사용자 행태 분석, 마케팅, 영업 전략 필수 정보 생성
- 비정형 로그는 용량이 방대하기에 성능과 확정성 시스템 필요

가. 초고속 수집 성능과 확장성
- 수집 대상 서버가 증가하면 수만큼 에이전트 수를 늘리는 방식
나. 데이터 전송 보장 메커니즘
- 다양한 저장소의 종류에 따라 수집에서 저장소까지의 양 종단점 간에 데이터 전송 안정성 수준 제어 필요
- 여러 단계를 거쳐 저장소에 도착할 수 있는데 단계별로 신호를 주고 받아서 이벤트 유실 방지
- 성능과 안정성은 트레이드 오프(Trade-Off)가 존재하며 비즈니스 특성 고려해 선택
다. 다양한 수집과 저장 플러그인
- 비정형 데이터는 소셜과 같은 서비스도 있으며, 기업 내부의 로그나 성능 데이터 수집 뿐만 아니라 잘 알려진 서비스를 수집할 수 있게 내장 플러그인 제공 필요
- 데이터 저장소도 하둡 저장은 기본이며, NoSQL을 포함한 다양한 DB에 저장하는 플러그인 제공 추세
라. 인터페이스 상속을 통한 애플리케이션 기능 확장
- 업무 특성상 서비스 기능을 수정할 수 있어야 하며 인터페이스를 확장해 용도에 맞게 수정
- 빅데이터 플랫폼을 구축할 때 수집 프로그램으로 플럼(Flume) 활용
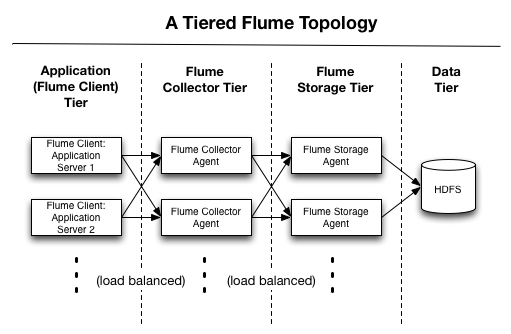
- 4단계에 걸쳐 플럼(Flume-NG)을 이용해 데이터 수집/저장
- 첫번째는 애플리케이션 단계, 두번째는 데이터 수집 단계, 세번째는 수집한 데이터를 저장하는 단계이며 네번째는 데이터 저장소 보관 단계
2. 대규모 분산 병렬 처리
- 한번에 처리해야 할 데이터가 수십 GB에서 수십 TB에 이르거나 대규모 컴퓨팅이 필요하면 적극적으로 하둡 검토 필요
- 하둡은 분산 병렬 처리의 업계 표준인 맵리듀스(MapReduce) 시스템과 분산 파일시스템인 HDFS로 구성된 플랫폼 기술
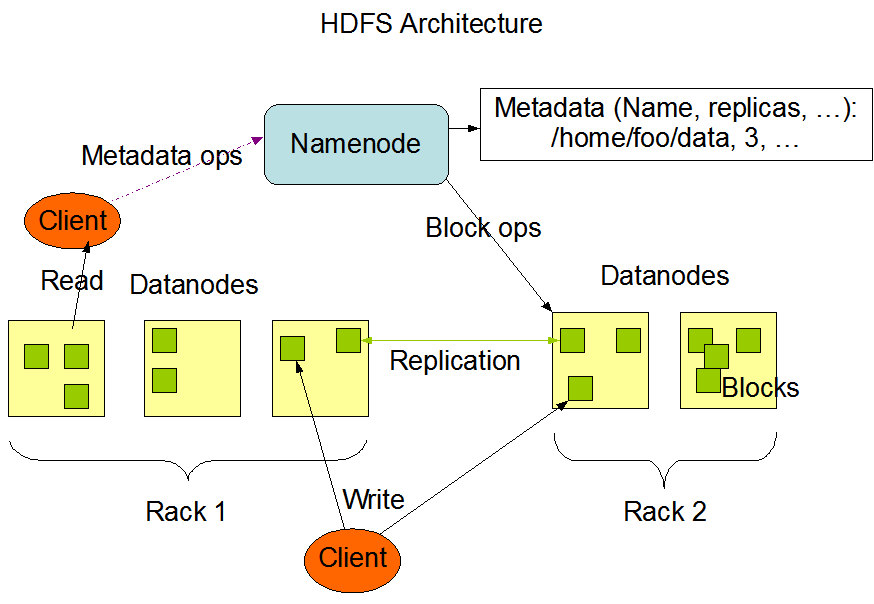
가. 선형적인 성능과 용량 확장
- 하둡을 구축한다는 것은 여러대의 서버로 클러스터를 만든다는 의미이며, 통상적으로 5대 정도가 최소 클러스터 수
- 하둡은 비공유(Shared Nothing) 분산 아키텍처 시스템이라 연산 기능과 저장 기능이 서버 대수에 비례해 증가
- 하둡은 2만 대의 서버들을 단일 클러스터로 구성할 수 있을 만큼 확장성이 뛰어나며 선형적 성능 확장 가능
나. 고장 감내성(Falut Tolerance)
- 데이터는 3중 복제가 돼 다른 물리서버에 저장하여, 특정 서버 장애 발생시 복제본이 존재하여 유실 방지
- 맵리듀스 수행 중 특정 태스크에서 장애가 발생시, 자동으로 감지해 특정 태스크만 다른 서버에서 재실행
다. 핵심 비즈니스 로직에 집중
- 개발자는 오직 비즈니스 로직에만 집중할 수 있으며, 시스템 수준에서 발생하는 장애 상황이나 확장성, 성능 등의 이슈는 하둡이 내부적으로 최적화 처리
- 시스템적인 장애 상황이 발생하더라도 자동 복구(failover) 수행
라. 풍부한 에코시스템 형성
- 데이터 수집 기술, Flume-NG
- 데이터 연동 기술, Sqoop
- 데이터베이스 기술인 NoSQL, HBase
- 대용량 SQL 질의 기술, Hive와 Pig
- 실시간 SQL 질의 기술, Impala, Tajo
- 워크플로 관리 기술, Oozie, Azkaban
3. 데이터 연동
- 기간계 시스템인 데이터베이스를 맵리듀스와 같은 대규모 분산 병렬 처리를 하는 것은 심한 부하 야기
- 데이터베이스의 데이터를 하둡으로 복사를 한 후 하둡에서 대규모 분산 병렬 처리를 수행
- 그 결과 생성된 요약된 작은 데이터셋을 다시 데이터베이스에 기록, 대표적인 솔루션으로 Sqoop
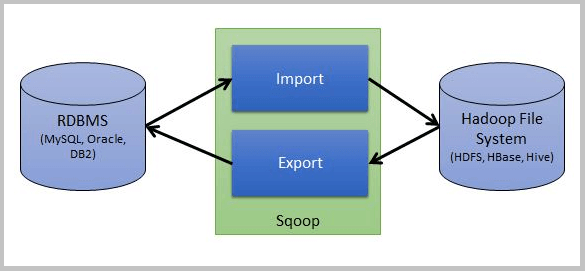
- 스쿱은 오라클(Oracle), MySQL, PostgreSQL, 사이베이스 등 JDBC를 지원하는 대부분의 RDBMS를 지원
- HBase와 같은 일부 NoSQL 데이터베이스와도 연동
가. 스쿱 스크립트
- 데이터를 가져올 DBMS 접속 정보 입력
- SQL을 입력
- 몇개의 프로세스 실행할지 지정 (프로세스가 많으면 빨리 가져오는 대신 부하 발생)
- DB의 키 컬럼(Key Column) 입력
- DB로 부터 가져온 데이터를 저장할 하둡 경로 지정
4. 대용량 질의 기술
- 하둡은 코딩이 필요하기 때문에 분석가에게 어려울 수 있고, 이러한 이유로 나온 것이 하이브(Hive)
- 하이브는 SQL를 이용하여 하둡상에 저장된 데이터를 처리하고 분석하는 도구
- 하이브는 실시간이 아니기에 SQL on Haoop이라는 실시간 SQL 질의 분석 기술 등장
SQL on Hadoop 기술들
- 아파치 드릴(Drill) : 하둡 전문 회사 MapR이 주축되어 진행, 드레멜의 아키텍처와 기능을 동일하게 구현한 오픈소스 버전의 드레멜
- 아파치 스팅거(Stringer) : 하둡 전문 회사 호튼웍스에서 개발 주도, 기존의 하이브 코드를 최대한 이용하여 개선
- 샤크(Shark) : 인메모리 기반의 대용량 데이터웨어하우징 시스템, 하이브와 호환되기에 하이브 SQL 질의와 사용자 정의 함수(User Defined Function) 사용
- 아파치 타조(Tajo) : 고려대 대학원에서 최초 시작, 국내 빅데이터 전문회사인 그루터(Gruter)에 합류하여 개발 진행
- 임팔라(Impala) : 하둡 전문 회사인 클라우데라(Cloudera)에서 개발
- 호크(HAWQ) : EMC에서 분산한 피보탈(Pivotal)에서 개발, 상용과 커뮤니티 2가지 버전 제공
- 프레스토 : 페이스북에서 자체적으로 개발 사용하는 Hadoop 기반의 데이터웨어하우징 엔진
References
[1] 데이터 분석 전문가 가이드
'IT 자격증 > 데이터 분석 전문가(ADP)' 카테고리의 다른 글
| 데이터베이스 클러스터(Database Cluster) - ADP #9 (0) | 2022.07.19 |
|---|---|
| 분산 파일 시스템 (Distributed File System) - ADP #8 (0) | 2022.05.02 |
| 데이터 연계 및 통합 기법 - ADP #6 (0) | 2022.04.30 |
| EAI(Enterprise Application Integration) - ADP #5 (0) | 2022.04.01 |
| CDC(변경 데이터 캡쳐, Change Data Capture) - ADP #4 (0) | 2022.03.31 |



