[카프카] 메세지 시스템, Kafka의 탄생
- 빅데이터 및 DB/카프카(Kafka)
- 2020. 11. 6.
카프카(Kafka)는 세계적인 소셜 구인구직 플랫폼인 링크드인에서 만든 스칼라로 개발한 메세지 프로젝트이다. 이 내부 시스템은 2011년 아파치(Apache) 공식 오픈소스로 공개되었으며 현재 엄청나게 많은 업체들이 이 시스템을 사용중에 있다.

해외뿐만 아니라 국내 유수의 IT업체들도 카프카를 사용중에 있다. 우선 IT 양대 산맥인 네이버(Naver)와 카카오(Kakao) 역시 이 시스템을 사용중에 있으며 카프카 홈페이지 첫화면을 보면 포츈(Fortune) 100개의 기업 중 카프카를 사용하는 기업이 80%라고 할 정도로 자체적인 메시지 시스템이 구축되지 않는 이상 카프카를 기본적으로 사용한다 봐도 무방할 정도다.
링크드인의 히스토리
링크드인(Linkedin)은 2002년 12월에 시작했으며 모바일 산업이 급속도로 성장하면서 기하급수적인 트래픽이 몰리게 된다. 링크드인은 이정도의 성공을 예상했는지 혹은 알지 못했는지는 모르겠지만, 기존에 구현한 시스템은 곧 위기에 봉착하게 된다.

링크드인의 내부 구성도를 보면 나름 Hadoop도 구축하고, 메세지 시스템을 사용하여 처리한 것을 알 수 있다. 즉 시대의 흐름을 잘 따르고 있었다. 하지만 서비스가 늘어나고, 전달해야 되는 메세지 수가 늘어날수록 현재의 구조로는 시스템을 운영할 수 없다는 사실을 깨닫고 만다.

Point to Point 구조였기 때문에 연결이 하나가 늘어날 경우 하나만 연결하면 되는 것이 아니라 수많은 시스템과 1:1로 연결하며 이는 유지보수 측면의 문제만 있는 것이 아니라 성능에도 치명적이었다. 그래서 메시지를 처리하는 팀은 새로운 프로젝트를 만들고자 하는데(물론 만들기 전에 기존 메시지 시스템을 조사해봤으나 마땅한 시스템이 없었다) 이때 나오는 시스템이 바로 카프카(Kafka)가 된다.
새로운 시스템의 요구사항
이벤트 규모
- 실 사용자가 1억명이 넘는 엄청난 규모의 이벤트양, 하루에 이벤트가 1조건이 넘게 발생할 정도
데이터 구조
- 서비스가 다양화되면서 메세지로 전달해줘야 되는 데이터의 구조가 계속 변화되는 문제
서비스의 지속
- 데이터는 안전하고 끊임없이 전달해줘야 한다
- 시스템 일부가 다운되어도 문제 없이 돌아가야 한다
메세지 처리
- 임의의 타이밍에 데이터를 읽을 수 있어야 한다
- 메세지를 잃지 않는다
※ 링크드인은 데이터의 규모와 구조의 다양성 그리고 서비스 지속의 니즈(Needs)로 인해 필연적으로 기존 시스템을 대체해야 하는 상황에 직면하였다.
새로운 시스템의 아키텍처 및 구성도
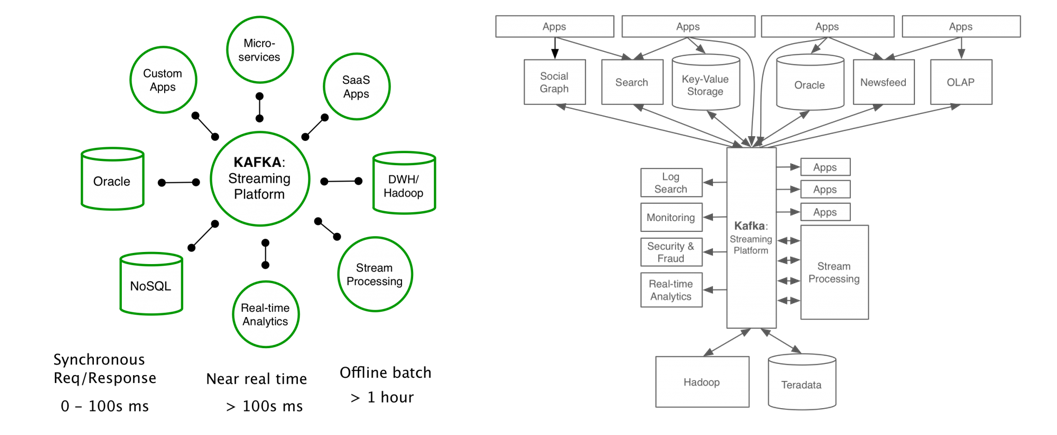
카프카 프로젝트 팀은 모든 데이터는 카프카를 통해서 주고 받는 것을 상상하였고 실제 구성도는 우측과 같은 모습이 되길 바랐다.
카프카의 명칭 유래
링크드인에서 볼드모트(Voldemort, 분산 Key-Value 저장소), 삼자(Samza, 스트림 처리 시스템)을 만든 제이 크렙스(Jay Kreps)는 대학 시절 문학 수업을 들으며 소설가 프란츠 카프카(Franz Kafka, 1883.7.3 ~ 1924.6.3)에 심취한 적이 있었다.

그는 새로운 메세지 시스템이 데이터 저장, 기록, 쓰기를 주로하는 시스템이었기 때문에 작가의 이름을 프로젝트로 하면 될 것이라 생각했으며, 가장 좋아했던 카프카를 프로젝트 이름으로 선정하게 되었다.
http://kafka.apache.org/
https://www.confluent.io/blog/event-streaming-platform-1/
'빅데이터 및 DB > 카프카(Kafka)' 카테고리의 다른 글
| [카프카] 리더, 팔로워와 리플리케이션(replication) (0) | 2020.11.12 |
|---|---|
| [카프카] 토픽(Topic)과 파티션(Partition) 이해 (0) | 2020.11.12 |
| [카프카] 페이지 캐시(Page Cache) (0) | 2020.11.12 |
| [카프카] Kafka의 분산 시스템 (0) | 2020.11.11 |
| [카프카] Pub/Sub 구조와 프로듀서, 컨슈머 (0) | 2020.11.10 |