카프카(Kafka)에서는 다양한 언어로 데이터를 주고 받는 기능을 제공하는데 본 포스팅은 파이썬(Python)으로 구현하는 프로듀서(producer)/컨슈머(consumer) 즉 데이터를 보내고 받는 방법을 설명한다.
파이썬으로 카프카를 호출하는 방법이 대표적으로 2가지 방법이 존재하는 것 같다. 하나는 카프카를 만든 제이 크렙스(Jay Kreps)가 만든 회사인 confluent가 제공하는 라이브러리이고, 다른 하나는 kafka-python이라는 라이브러리를 사용하는 방법이다. 후자인 kafka-python을 범용적으로 많이 사용하는데 성능은 컨플루언트의 라이브러리가 더 좋다.

후자를 사용하는 이유는 단하나 confluent는 c로 만든 라이브러리를 호출하여 사용하는 방식이라 별도의 설치과정이 존재하기 때문이다. 즉 성능을 중시 여긴다면 c로 만든 confluent를 사용하면 될 것이고, 쉽게 사용하는 것을 목적으로 한다면 후자를 사용해도 상관이 없을 것이다.
kafka-pyhon 라이브러리 설치
pip install kafka-python
Producer 구현
라이브러리를 설치했으면 아래와 같은 코드를 작성하고 실행해본다.
from kafka import KafkaProducer
from json import dumps
import time
producer = KafkaProducer(acks=0, compression_type='gzip', bootstrap_servers=['localhost:9092'],
value_serializer=lambda x: dumps(x).encode('utf-8'))
start = time.time()
for i in range(10000):
data = {'str' : 'result'+str(i)}
producer.send('test', value=data)
producer.flush()
print("elapsed :", time.time() - start)위 코드는 json 형태로 data를 생성하는데 "result"라는 문자열에 + i값을 만번까지 증가시켜서 test라는 토픽으로 보내는 내용이다. 실행을 하게 되면 최종적으로는 만번 전달하는데 걸린 시간이 출력이 되는 것인데 필자는 다음과 같은 속도가 나왔다.
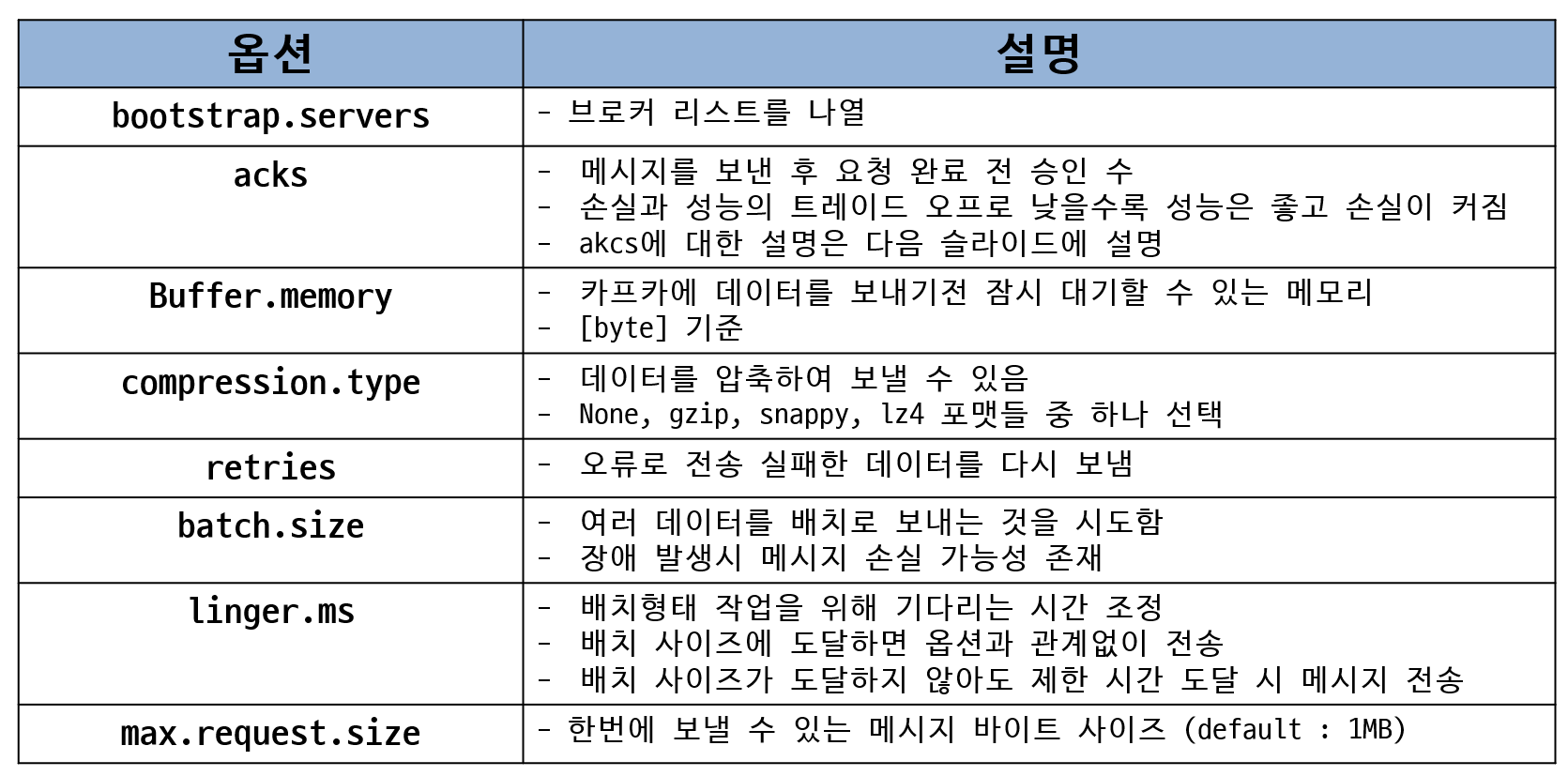
프로듀서 옵션
KafkaProducer를 선언할 때 acks가 0으로 확인 없이 전송하며, compression_type이 gzip으로 gzip형태로 압축하여 전송을 한다. 그리고 카프카 서버가 여러대일 경우 bootstrap_servers에 브로커 리스트를 배열 값으로 지정을 하면 되며 자세한 옵션 정보는 아래와 같다.
Produce 결과
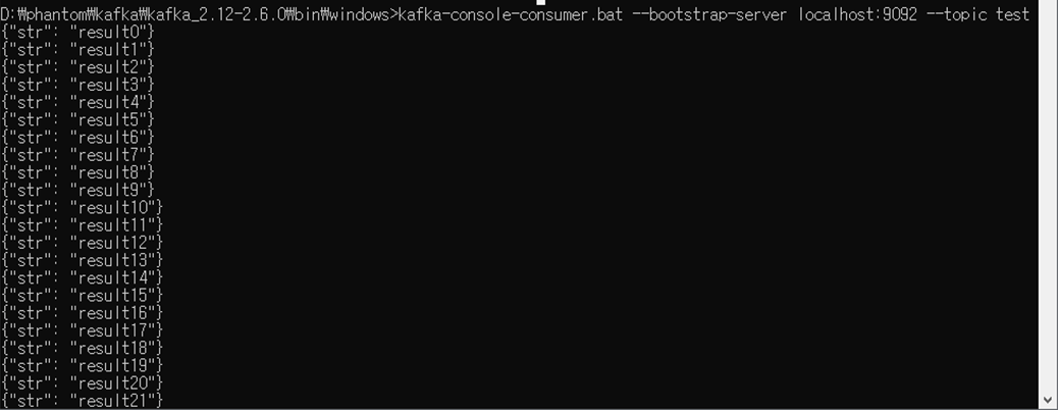
C:\Users\user\anaconda3\python.exe D:/rainbow/application/producer.py
elapsed : 5.04697060585022
Process finished with exit code 0만번 전송하는데 5.04초가 걸렸으니 초당 약 2천건 정도 보내졌다는 것을 알 수 있다.
Consumer 구현
이제 데이터를 전송했으면 받는 부분인 consumer를 구현해보도록 한다.
from kafka import KafkaConsumer
from json import loads
# topic, broker list
consumer = KafkaConsumer(
'test',
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='my-group',
value_deserializer=lambda x: loads(x.decode('utf-8')),
consumer_timeout_ms=1000
)
# consumer list를 가져온다
print('[begin] get consumer list')
for message in consumer:
print("Topic: %s, Partition: %d, Offset: %d, Key: %s, Value: %s" % (
message.topic, message.partition, message.offset, message.key, message.value
))
print('[end] get consumer list')Consumer를 선언할 때, test라는 topic을 기준으로 카프카 서버는 localhost를 지정하였다.
Consumer 옵션
| 옵션 | 설명 |
| bootstrap_servers | 카프카 클러스터들의 호스트와 포트 정보 리스트 |
| auto_offset_reset | earliest : 가장 초기 오프셋값 latest : 가장 마지막 오프셋값 none : 이전 오프셋값을 찾지 못할 경우 에러 |
| enable_auto_commit | 주기적으로 offset을 auto commit |
| group_id | 컨슈머 그룹을 식별하기 위한 용도 |
| value_deserializer | producer에서 value를 serializer를 했기 때문에 사용 |
| consumer_timeout_ms | 이 설정을 넣지 않으면 데이터가 없어도 오랜기간 connection한 상태가 된다. 데이터가 없을 때 빠르게 종료시키려면 timeout 설정을 넣는다. |
Consumer 결과
C:\Users\user\anaconda3\python.exe D:/rainbow/application/consumer.py
[begin] get consumer list
Topic: test, Partition: 0, Offset: 0, Key: None, Value: {'str': 'result0'}
Topic: test, Partition: 0, Offset: 1, Key: None, Value: {'str': 'result1'}
Topic: test, Partition: 0, Offset: 2, Key: None, Value: {'str': 'result2'}
Topic: test, Partition: 0, Offset: 3, Key: None, Value: {'str': 'result3'}
Topic: test, Partition: 0, Offset: 4, Key: None, Value: {'str': 'result4'}
...
Topic: test, Partition: 0, Offset: 9996, Key: None, Value: {'str': 'result9996'}
Topic: test, Partition: 0, Offset: 9997, Key: None, Value: {'str': 'result9997'}
Topic: test, Partition: 0, Offset: 9998, Key: None, Value: {'str': 'result9998'}
Topic: test, Partition: 0, Offset: 9999, Key: None, Value: {'str': 'result9999'}
[end] get consumer list
Process finished with exit code 0
위 예제는 간단히 확인해보는 예제로 로그성 데이터가 아니라 중요한 데이터를 가져와야 되는 경우 설정이 중요해질 수 있기 때문에 github에 있는 예제들을 확인하는 것이 좋을 것이다.
python-kafka github
https://github.com/dpkp/kafka-python
'빅데이터 및 DB > 카프카(Kafka)' 카테고리의 다른 글
| [카프카] 주키퍼 및 카프카 설치 및 테스트(윈도우) (0) | 2020.11.16 |
|---|---|
| [카프카] 리더, 팔로워와 리플리케이션(replication) (0) | 2020.11.12 |
| [카프카] 토픽(Topic)과 파티션(Partition) 이해 (0) | 2020.11.12 |
| [카프카] 페이지 캐시(Page Cache) (0) | 2020.11.12 |
| [카프카] Kafka의 분산 시스템 (0) | 2020.11.11 |