KNN(k최근접) 알고리즘 설명 및 구현하기
- 인공지능 및 데이터과학 / 머신러닝 및 딥러닝
- 2022. 1. 31.
KNN 알고리즘 개념
k최근접 알고리즘(k-nearest neighbors algorithm, KNN) 알고리즘은 분류(classify) 문제에도 사용할 수 있고, 회귀(Regression) 문제에도 사용할 수 있으며, 수많은 알고리즘의 중간 과정(예를 들어 추천 알고리즘인 CF에서도 사용)에서도 자주 쓰이는 알고리즘이다.

KNN의 k라는 것은 숫자를 뜻하며 여기에 숫자는 이웃이고, k만큼의 이웃을 지정하여 그 이웃들의 값을 토대로 계산한다. KNN은 쉽게 생각하면 유사 알고리즘과 같다 컬럼별로 유사한 이웃들을 찾아서 값을 계산하고, 이를 통해 최종적으로 분류 및 회귀 문제를 풀기 때문이다.
키와 몸무게를 기반으로 헌병과 그외의 보직을 예측한다고 가정을 해보자. 이는 실제 데이터가 아니라 어디까지나 예시를 들기 위해서 만든 데이터임을 참고하자
| 키(cm) | 몸무게(kg) | 보직 |
| 175cm | 70kg | 그외 |
| 180cm | 80kg | 헌병 |
| 183cm | 73kg | 헌병 |
| 172cm | 75kg | 그외 |
| 185cm | 70kg | 헌병 |
| 178cm | 68kg | 헌병 |
| 173cm | 58kg | 그외 |
| 180cm | 75kg | 그외 |
위 데이터를 보면, 사실 몸무게는 중요한 수치가 아니라 키가 중요하지만 KNN의 시각화를 보여주기 위해서는 2개 이상의 독립변수가 있어야 좋기 때문에 설정해보았다.
KNN의 프로세스
KNN을 분석하기 위한 프로세스는 우선 K를 선정한다. K를 지정할 때 너무 낮게(ex: 1)로 설정할 경우 overfitting 문제가 발생한다. 예를 들어 모든 데이터가 이쁘게 분류되면 좋겠지만 위의 데이터를 보면, 180cm인데 보직이 헌병이 아니며 178cm인데 헌병인 보직이 있다.
이렇게 예상치 못한 데이터들이 들어가 있기 때문에 정확도를 높이기 위해서는 k의 수치를 일정 이상을 주는 것이 중요하다. 그렇다고 너무 높게 주는 것도 문제가 있다. k를 높게 주면 모든 데이터가 일반화 되어서 유의미한 분석을 못할 수도 있기 때문이다.

즉, KNN의 프로세스에서 가장 중요한 프로세스가 K를 선택하는 것인데 k를 선택하는 방법은 가능한 k의 값을 모두 테스트를 해봐서 가장 성능이 높았던 수치를 선택하는 것이 당연하게도 제일 정확하다.
k를 선택하였으면 기준이 되는 데이터와 데이터간의 유클리드 거리를 계산하여, 가장 가까운 k개의 이웃을 선택하며 이 선택한 레코드들의 레이블을 기준으로 기준의 분류 혹은 회귀값을 예측한다.
위에 있는 것이 KNN 분석의 모든 것이다. 물론 중간중간 무의미한 독립변수를 변경하기도 하고, 독립변수를 변경함과 동시에 또 KNN을 돌려보면서 성능을 계속 체크할 순 있지만 일단 위 프로세스를 반복하는 것일 뿐 더이상은 없다. 사실 위 내용을 기반으로 직접 KNN 알고리즘을 만들라고 해도 매우 쉽지만, 이미 수많은 라이브러리들이 이를 제공하니 여기선 Python 기반으로 예제를 분류하는 실습을 해보도록 하겠다.
Python 구현
라이브러리 및 데이터 로드
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
import numpy as np
# 아이리스 데이터 세팅
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=4)
print ('Train set:', X_train.shape, y_train.shape)
print ('Test set:', X_test.shape, y_test.shape)우선 분류 문제에 가장 대표적인 붓꽃(아이리스, iris)를 기반으로 구현을 해보도록 한다. 그전에 라이브러리는 iris를 읽고 모델을 만들기 위해서 사이킷런(sklearn)을 사용하고, 분석용 데이터로 변환 등을 하는 것으로 넘파이(numpy) 마지막으로 시각화를 위해서 맷플롭립(matplotlib)을 쓴다.
datasets를 import하면 자체 저장된 아이리스를 언제뜬지 꺼내쓸 수 있는데 load_iris를 하면 된다. 그리고 이 iris 데이터는 iris.data와 iris.target으로 X와 y를 손쉽게 호출할 수 있다.
아이리스 데이터를 로드 후, train_test_split를 호출하여, test 사이즈는 0.2로 지정하였다. random_state는 동일한 데이터를 얻기 위함이기 때문에 아무값이나 해도 상관은 없다. 위 내용을 print로 출력하여 train과 test를 shape을 호출하면
Train set: (120, 4) (120,)
Test set: (30, 4) (30,)
20%의 test 셋이 잘 세팅된 것을 확인할 수 있다.
KNN 학습 및 예측
# KNN 알고리즘
k = 1
clf = KNeighborsClassifier(n_neighbors = k).fit(X_train,y_train)
print(clf)
yhat = clf.predict(X_test)
print("Train set Accuracy: ", metrics.accuracy_score(y_train, clf.predict(X_train)))
print("Test set Accuracy: ", metrics.accuracy_score(y_test, yhat))
KNN의 K 초기값으로 1를 주었고, KNeighborsClassifier를 호출하여, Train을 학습한 결과값을 clf 라는 이름으로 모델을 생성하였다.
KNeighborsClassifier(n_neighbors=1)
그리고 clf 모델을 이용하여 X_test 데이터를 예측한 결과값을 yhat에 담고, accuracy(정확도)를 측정한 결과는 아래와 같다.
Train set Accuracy: 1.0
Test set Accuracy: 0.9333333333333333
위 데이터를 보다시피, Train은 당연하다고 쳐도 Test의 Accuracy도 93% 이상으로 꽤 높은 것을 알 수 있다. 한마디로 knn의 알고리즘으로 붓꽃의 분류를 효과적으로 할 수 있다는 의미이다. 이제 이 모델을 정확도를 위해서 튜닝을 해보도록 한다.
최적 K값 찾기
knn의 알고리즘의 튜닝 핵심은 적절한 k값을 찾는 것이기 때문에 k=1이 아닌 다른 값으로 호출을 해본다. 사람이 일일이 할수도 있지만 효과적이지 않으며 데이터가 바뀔 때마다 k의 값이 변경될 수 있기 때문에 자동화해야 한다.
# 최적K 찾기
Ks = 10
mean_acc = np.zeros((Ks - 1))
std_acc = np.zeros((Ks - 1))
for n in range(1, Ks):
# Train Model and Predict
clf = KNeighborsClassifier(n_neighbors=n).fit(X_train, y_train)
yhat = clf.predict(X_test)
mean_acc[n - 1] = metrics.accuracy_score(y_test, yhat)
print(mean_acc)위 로직은 최대 k를 10번까지 작업을 진행하며, 매번 학습한 결과의 test 정확도를 mean_acc 배열에 저장하고 있는다.
1~10=k의 Test Accuracy
[0.93333333 0.93333333 0.96666667 0.96666667 0.96666667 0.96666667 0.96666667 0.96666667 0.96666667]
위 데이터를 눈으로 봐도 알순 있지만, 좀 더 시각적으로 보여주기 위해서 matplotlib을 써보도록 한다.
KNN 시각화
# 시각화
plt.plot(range(1,Ks),mean_acc,'g')
plt.ylabel('Accuracy ')
plt.xlabel('Number of Neighbors (K)')
plt.tight_layout()
plt.show()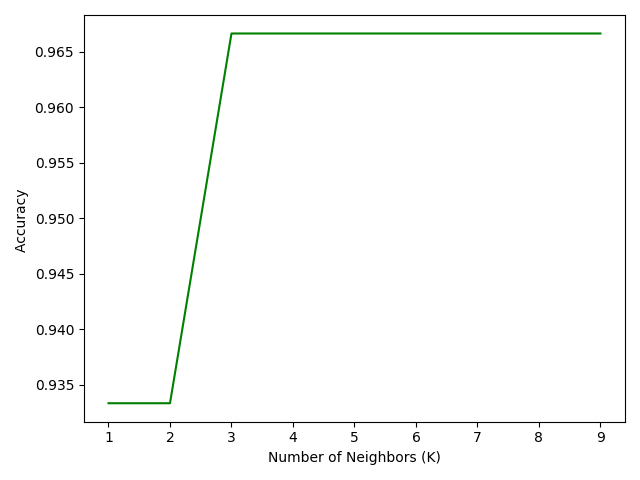
위와 같이 결과는 1~2가 동일하게 나오다가 3부터 성능이 올라갔는데 3이후부터는 값이 동일하다. 즉 여기서 최적의 knn은 3이 된다.
최적의 KNN의 값
print( "The best accuracy was with", mean_acc.max(), "with k=", mean_acc.argmax()+1)The best accuracy was with 0.9666666666666667 with k= 3
최적의 KNN의 값은 위와 같이 mean_acc.argmax()+1을 호출하면 최적의 값을 호출한다. (여기선 3)
최종소스
from sklearn import datasets
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
import matplotlib.pyplot as plt
import numpy as np
# 아이리스 데이터 세팅
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=4)
print ('Train set:', X_train.shape, y_train.shape)
print ('Test set:', X_test.shape, y_test.shape)
# KNN 알고리즘
k = 1
clf = KNeighborsClassifier(n_neighbors = k).fit(X_train,y_train)
print(clf)
yhat = clf.predict(X_test)
print("Train set Accuracy: ", metrics.accuracy_score(y_train, clf.predict(X_train)))
print("Test set Accuracy: ", metrics.accuracy_score(y_test, yhat))
# 최적K 찾기
Ks = 10
mean_acc = np.zeros((Ks - 1))
std_acc = np.zeros((Ks - 1))
for n in range(1, Ks):
# Train Model and Predict
clf = KNeighborsClassifier(n_neighbors=n).fit(X_train, y_train)
yhat = clf.predict(X_test)
mean_acc[n - 1] = metrics.accuracy_score(y_test, yhat)
print(mean_acc)
# 시각화
plt.plot(range(1,Ks),mean_acc,'g')
plt.ylabel('Accuracy ')
plt.xlabel('Number of Neighbors (K)')
plt.tight_layout()
plt.show()
print( "The best accuracy was with", mean_acc.max(), "with k=", mean_acc.argmax()+1)
References
- Coursera IBM, Machine Learning with Python
연관자료
유클리디안 거리(Euclidean Distance) 개념과 구현해보기
'인공지능 및 데이터과학 > 머신러닝 및 딥러닝' 카테고리의 다른 글
| DBSCAN clustering 이해하기(밀도기반 알고리즘) (0) | 2022.02.12 |
|---|---|
| K-means clustering Python으로 구현하기 (0) | 2022.02.09 |
| 결정 트리(Decision Tree) 설명 및 분류기 구현 (0) | 2022.01.17 |
| [Python] 해밍 거리(Hamming distance) 이해 및 구현하기 (0) | 2022.01.13 |
| 자카드 유사도(Jaccard Similarity) 개념 이해 및 Python 구현 (0) | 2022.01.09 |



